002 大模型LLM-微调经验分享&总结-知乎-刘聪NLP
转载
本文转载于:@知乎-刘聪NLP
写在前面
大型语言模型横行,之前非常焦虑,现在全面拥抱。目前也有很多开源项目进行大模型微调等,笔者也做了一阵子大模型了,特此来介绍一下ChatGLM-6B模型微调经验,并汇总了一下目前开源项目&数据。笔者与很多人微调结论不同,本人在采用单指令上进行模型微调,发现模型微调之后,「并没有出现灾难性遗忘现象」。
ChatGLM-6B模型微调(关系抽取)
模型越大对显卡的要求越高,目前主流对大模型进行微调方法有三种:Freeze方法、P-Tuning方法和Lora方法。笔者也通过这三种方法,在信息抽取任务上,对ChatGLM-6B大模型进行模型微调。为了防止大模型的数据泄露,采用一个领域比赛数据集-汽车工业故障模式关系抽取,随机抽取50条作为测试集。
详细代码见上面的GitHub链接,并且也被ChatGLM官方收录。
Freeze方法
Freeze方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行TP或PP操作,就可以对大模型进行训练。
微调代码,见finetuning_freeze.py,核心部分如下:
1 | for name, param in model.named_parameters(): |
针对模型不同层进行修改,可以自行修改。训练代码均采用DeepSpeed进行训练,可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text等,可根据自己的任务配置。
1 | CUDA_VISIBLE_DEVICES=0 DeepSpeed finetuning_freeze.py --num_train_epochs 5 |
三元组抽取的推理代码,见predict_freeze.py,其他任务可以根据自己的评价标准进行推理预测。
P-Tuning方法
P-Tuning方法,参考ChatGLM官方代码 ,是一种针对于大模型的soft-prompt[1]方法。
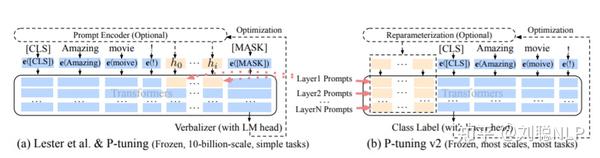
P-Tuning,仅对大模型的Embedding加入新的参数。P-Tuning-V2,将大模型的Embedding和每一层前都加上新的参数。
微调代码,见finetuning_pt.py,核心部分如下:
1 | config = ChatGLMConfig.from_pretrained(args.model_dir) |
当prefix_projection为True 时,为P-Tuning-V2方法,在大模型的Embedding和每一层前都加上新的参数;
当prefix_projection为False时,为P-Tuning方法, 仅在大模型的Embedding上新的参数。
可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text、pre_seq_len、prompt_text等, 可根据自己的任务配置。
1 | CUDA_VISIBLE_DEVICES=0 DeepSpeed finetuning_pt.py --num_train_epochs 5 |
三元组抽取的推理代码,见predict_pt.py,其他任务可以根据自己的评价标准进行推理预测。
Lora方法
Lora方法,即在大型语言模型上对指定参数增加额外的低秩矩阵,并在模型训练过程中,仅训练而外增加的参数。当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量很小,达到仅训练很小的参数,就能获取较好的结果。
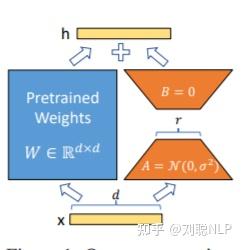
微调代码,见finetuning_Lora.py,核心部分如下:
1 | model = ChatGLMForConditionalGeneration.from_pretrained(args.model_dir) |
可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text、Lora_r等,可根据自己的任务配置。
1 | CUDA_VISIBLE_DEVICES=0 DeepSpeed finetuning_Lora.py --num_train_epochs 5 |
三元组抽取的推理代码,见predict_Lora.py,其他任务可以根据自己的评价标准进行推理预测。
注意:对于结果需要保持一致的任务(即关掉dropout,解码关掉do_sample),需要保存模型的adapter_config.json文件中,inference_mode参数修改成false,并将模型执行model.eval()操作。 主要原因是chatglm模型代码中,没有采用Conv1D函数。
实验方法
三元组抽取
- 模型训练时,最大长度为768,Batch大小为2,训练轮数为5,fp16训练,采用
DeepSpeed的Zero-1[2]训练; P-Tuning V2训练方法,PT-Only-Embedding表示仅对Embedding进行soft-prompt,Freeze仅训练模型后五层参数,Lora采用低秩矩阵方法训练,秩为8;- 由于之前训练PT在48G-A40显卡上会出现
OOM[3],因此之前进行PT实验时对模型开启了gradient_checkpointing_enable[4],使得模型显存占用变小,但训练时长增加。 - 训练示例:
1 | prompt_text:你现在是一个信息抽取模型,请你帮我抽取出关系内容为\"性能故障\", |
时间换空间,可用很好的解决显卡的资源问题,简单玩玩还可以,如果想要模型达到最优效果或可用快速看到效果,还不如租张A100卡,快速实验,推理阶段再用自己的小破卡。
下面实验结果均是在租的80G-A100上进行的实验,与GitHub里用的A40的实验结果会有些差异,主要在训练时长(纯训练速度,剔除模型保存的时间)。说实话,真的要训练一个大模型,多个A100是必不可少的,可以减少很多模型并行的操作,效果上也更好把控一些。
| 微调方法 | PT-Only-Embedding |
P-Tuning V2 |
Freeze |
Lora |
|---|---|---|---|---|
| 显卡占用 | 37G | 56G | 24G | 39G |
| 总参数 | 6.259B | 7.211B | 6.255B | 6.259B |
| 可训练参数占比 | 0.0586% | 13.26% | 16.10% | 0.0586% |
| 训练耗时 | 20min | 52min | 46min | 25min |
| 测试结果F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
结果分析:
- 效果为
P-Tuning V2>Freeze>Lora>PT-Only-Embedding; - 速度为
PT-Only-Embedding>Lora>Freeze>P-Tuning V2; PT-Only-Embedding效果很不理想,发现在训练时,最后的loss仅能收敛到2.几,而其他机制可以收敛到0.几。分析原因为,输出内容形式与原有语言模型任务相差很大,仅增加额外Embedding参数,不足以改变复杂的下游任务;P-Tuning V2方法占用显存更大,因为也增加了很多而外参数;- 测试耗时,采用float16进行模型推理,由于其他方法均增加了额外参数,因此其他方法的推理耗时会比
Freeze方法要高。当然由于是生成模型,所以生成的长度也会影响耗时; - 模型在指定任务上微调之后,并没有丧失原有能力,例如生成“帮我写个快排算法”,依然可以生成-快排代码;
- 由于大模型微调都采用大量
instruction进行模型训练,仅采用单一的指令进行微调时,对原来其他的指令影响不大,因此并没导致原来模型的能力丧失; - 上面测试仅代表个人测试结果。
很多同学在微调后出现了灾难性遗忘现象,但我这边并没有出现,对“翻译任务”、“代码任务”、“问答任务”进行测试,采用freeze模型,可以用test_forgetting.py进行测试,具体测试效果如下:
- 翻译任务

- 代码任务

- 问答任务

后面会把生成任务、分类任务做完,请持续关注GitHub,会定期更新。(太忙了,会抓紧时间更新,并且官方代码也在持续更新,如遇到代码代码调不通的情况,请及时联系我,我在GitHub也给出了我的代码版本和模型版本)
文本生成
- 为了防止大模型的数据泄露,采用一个“万创杯”中医药天池大数据竞赛-中医文献问题生成挑战,随机抽取20条作为测试集
- PT为官方的
P-Tuning V2训练方法,PT-Only-Embedding表示仅对Embedding进行soft-prompt,Freeze仅训练模型后五层参数,Lora采用低秩矩阵方法训练,秩为8; - 训练示例:
1 | prompt_text:你现在是一个问题生成模型,请根据下面文档生成一个问题,文档: |
模型训练,以Freeze方法为例:
1 | CUDA_VISIBLE_DEVICES=0 nohup DeepSpeed --master_port 5555 finetuning_freeze.py |
由于生成模型的内容不能想信息抽取任务一样评价,用现有的BLUE或者Rouge来评价也是不合适,因此制定了评分规则。 通过多样性和准确性两个角度判断D2Q模型好坏,每个样本总计5分,共20个样本。
多样性:
问题是否高度相似,每重复一个问题扣0.25分;
问题对应答案是否相同,每有一个重复答案或找不到答案,扣0.25分;
准确性:
问题能否从文档中找到答案,每有一个找不到答案,扣0.25分;
- 问题内容是否流畅,每有一个问题不流畅,扣0.25分;
- 问题内容是否有害,每有一个有害,扣0.25分;
测试数据见d2q_result_data/,测试代码见predict_d2q.py
| 微调方法 | 原始模型 | PT-Only-Embedding |
P-Tuning V2 |
Freeze |
Lora |
|---|---|---|---|---|---|
| 分数 | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
中文开源大模型&项目
虽然出来很多大模型,但Open的&中文可直接使用的并不多,下面对中文开源大模型、数据集和项目进行一下汇总。
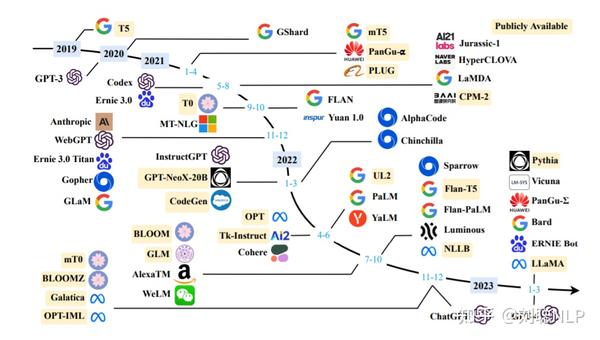
中文开源大模型
直接可微调,无需指令增量训练:
原始模型多语言or英文,需要中文指令数据集+增量训练:
中文开源指令数据
下面中文指令集,大多数从Alpaca翻译而来,请看下面项目中data目录。目前通过ChatGPT或者GPT4作为廉价标注工为自己的数据进行数据标注一个不错的思路。
开源项目
总结下面较火的开源项目:
总结
目前各大厂的大模型陆陆续续放出,堪称百家争鸣!个人玩家也是全面拥抱,想尽一切办法来训练微调大模型。只愿大家以后可以实现“大模型”自由。愿再无“model-as-a-service”。
专有名词解释
soft-prompt方法
是一种用于生成文本的技术。在自然语言处理中,生成文本是指根据给定的输入生成相关的文本输出。soft-prompt方法是一种生成文本的方法,它使用给定的软提示(soft prompt)来指导生成的文本。
软提示是一种对生成文本的要求或指导。它可以是一个短语、一个问题或一个主题。软提示提供了一定的上下文,帮助模型理解要生成的文本应该具有的特定特征或内容。通过提供软提示,可以引导模型生成与提示相关的文本。soft-prompt方法可以应用于各种生成文本的任务,如机器翻译、文本摘要、对话系统等。它可以提高生成文本的质量和相关性,使得生成的文本更符合预期的要求。
软提示方法与传统的生成文本方法相比,具有更大的灵活性和可控性。通过调整软提示的内容和形式,可以对生成的文本进行更精确的控制,使其满足特定的需求或要求。这使得软提示方法成为生成文本领域中的一种重要技术。
DeepSpeed的Zero-1
DeepSpeed的Zero-1是一个优化训练大型模型的技术。DeepSpeed是一个开源的深度学习优化库,可以显著提高训练速度和模型规模。Zero-1是DeepSpeed中的一种优化技术,专门用于减少模型参数的内存占用和通信开销。Zero-1通过将模型参数分成多个小块,只在每个小块上进行计算和通信,从而减少了每次计算和通信的数据量。这种方式可以有效地降低模型参数的内存占用和通信开销,特别适用于训练大型模型。
通过使用Zero-1,DeepSpeed可以在不增加额外计算和通信开销的情况下,将模型规模扩展到更大的尺寸。这对于训练更复杂的模型和处理更大规模的数据集非常有帮助。同时,Zero-1还可以提高训练速度,因为减少了每次计算和通信的数据量,从而减少了训练的总体时间。
总之,DeepSpeed的Zero-1是一种优化技术,通过减少模型参数的内存占用和通信开销,可以提高训练大型模型的效率和速度。
出现OOM的原因和解决方法
OOM是Out of Memory的缩写,指的是内存不足。在深度学习训练中,OOM通常是由以下原因引起的:
- 模型复杂度高:深度学习模型通常包含大量的参数和层,需要大量的内存来存储模型的权重和中间计算结果。如果模型过于复杂,超出了可用内存的限制,就会出现
OOM。 - 批量大小过大:在深度学习训练中,通常会将训练数据划分为小批量进行处理。每个批量的数据会被同时输入到模型中进行计算,因此批量大小会直接影响内存的使用。如果批量大小设置过大,超出了可用内存的限制,就会出现OOM。
- 图像分辨率过高:在图像处理任务中,高分辨率的图像会占用更多的内存。如果输入的图像分辨率过高,超出了可用内存的限制,就会出现
OOM。 - 内存泄漏:内存泄漏是指程序在运行过程中无法释放已经分配的内存,导致内存占用不断增加。如果深度学习训练过程中存在内存泄漏问题,最终会导致内存不足而出现
OOM。
为解决OOM问题,可以采取以下措施:
- 减小模型复杂度:可以尝试减少模型的参数量或层数,以降低内存需求。
- 减小批量大小:可以尝试减小每个批量的数据量,以降低内存需求。但需要注意,较小的批量大小可能会影响训练的效果。
- 降低图像分辨率:可以尝试将输入图像的分辨率降低,以减少内存占用。
- 检查和修复内存泄漏问题:可以通过代码审查和内存分析工具来检查是否存在内存泄漏问题,并进行修复。
- 使用更大的内存或分布式训练:如果以上措施无法解决
OOM问题,可以考虑增加可用内存的限制,例如使用更大内存的计算设备或采用分布式训练的方式。
gradient_checkpointing_enable梯度检查点技术
是一个参数或选项,用于启用梯度检查点技术。梯度检查点技术是一种优化方法,用于减少计算图中的内存消耗,特别适用于深度学习模型中的大型计算图。
在训练过程中,计算图中的每个操作都会保存其梯度信息,以便在反向传播时使用。然而,对于具有大量参数和层的模型,这些梯度信息可能会占用大量内存。
梯度检查点技术通过在计算图中的某些操作处保存中间状态,而不是保存所有操作的梯度信息,来减少内存消耗。
这样,在反向传播过程中,只需要重新计算从检查点开始的操作的梯度,而不是重复计算整个计算图的梯度。
通过启用gradient_checkpointing_enable,可以在训练过程中使用梯度检查点技术来减少内存消耗。