003【LLM】从零开始训练大模型-知乎-何枝
转载
本文转载于:@知乎-何枝
在这篇文章中,我们将尽可能详细地梳理一个完整的
LLM训练流程。包括模型预训练Pretrain、tokenizer训练、指令微调Instruction Tuning、奖励模型Reward Mod和强化学习RLHF等环节。由于内容比较多,我们将逐步整理并完善这个文档。
预训练阶段Pretraining Stage
当前,不少工作选择在一个较强的基座模型上进行微调,且通常效果不错(如:[alpaca]、[vicuna] 等)。
这种成功的前提在于:预训练模型和下游任务的差距不大,预训练模型中通常已经包含微调任务中所需要的知识。
但在实际情况中,我们通常会遇到一些问题,使得我们无法直接使用一些开源 backbone:
| 续写任务测试 | LLaMA | MPT |
|---|---|---|
| 杭州西湖是 | 杭州西湖是杭州的一个静静的一个游泳池,游泳池是杭州西湖的一个游泳池,游泳池是杭州西湖的一个游泳池,游泳池是杭州西湖的一个游泳池,� | 杭州西湖是中国最大的湖泊,是中国最大的湖泊,是中国最大的湖泊,是中国最大的湖泊,是中国最大的湖泊,是中国最大的湖泊,是中国最大的湖泊, |
| 琅琊榜的导演是 | 琅琊榜的导演是很多的人都不知道,因为他的父亲是一位杰作家,他的父亲的杰作家是一位杰作家, | 琅琊榜的导演是谁?Who are the directors of the Rolling Stone?琅琊榜的导演是谁?Who are the |
- 专业知识不足:当我们需要一个专业领域的
LLM时,预训练模型中的知识就尤为重要。由于大多数预训练模型都是在通用训练语料上进行学习,对于一些特殊领域(金融、法律等)中的概念和名词无法具备很好的理解。我们通常需要在训练语料中加入一些领域数据(如:[xuanyuan 2.0]),以帮助模型在指定领域内获得更好的效果。

基于上述原因,我们在进行 SFT[1]步骤之前,先来看看预训练任务是如何做的。
tokenizer Training词表扩充
在进行预训练之前,我们需要先选择一个预训练的模型基座。
一个较为普遍的问题是:大部分优秀的语言模型都没有进行充分的中文预训练,
因此,许多工作都尝试将在英语上表现比较优秀的模型用中文语料进行二次预训练,期望其能够将英语上的优秀能力迁移到中文任务中来。
已经有许多优秀的仓库做过这件事情,比如:[Chinese-LLaMA-Alpaca]。
但在进行正式的训练之前,我们还有一步很重要的事情去做:词表扩充。
通俗来讲,tokenizer 的目的就是将一句话进行切词,并将切好词的列表喂给模型进行训练。
例如:
1 | 输入句子 >>> 你好世界 |
通常,tokenizer 有 2 种常用形式:WordPiece 和 BPE。
WordPiece
WordPiece 很好理解,就是将所有的「常用字」和「常用词」都存到词表中,
当需要切词的时候就从词表里面查找即可。
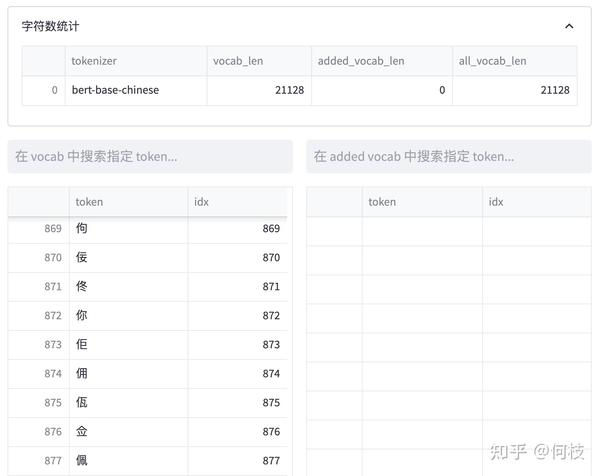
上述图片来自可视化工具 [tokenizer_viewer]。
如上图所示,大名鼎鼎的 BERT 就使用的这种切词法。
当我们输入句子:你好世界,
BERT 就会依次查找词表中对应的字,并将句子切成词的组合。
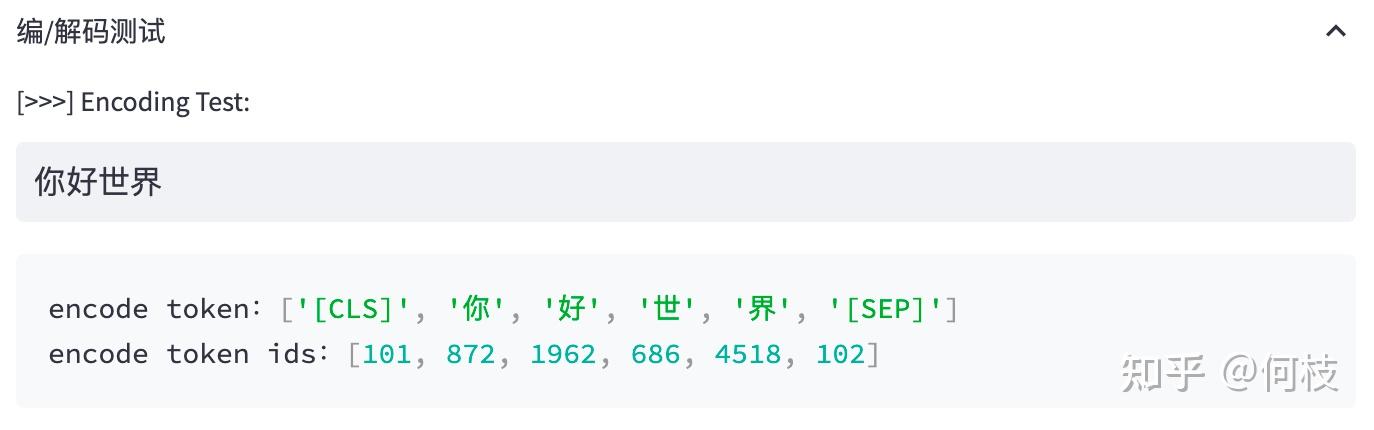
当遇到词表中不存在的字词时,tokenizer 会将其标记为特殊的字符 [UNK]:
Byte Pair Encoder(BPE)
WordPiece 的方式很有效,但当字词数目过于庞大时这个方式就有点难以实现了。
对于一些多语言模型来讲,要想穷举所有语言中的常用词(穷举不全会造成 OOV),
既费人力又费词表大小,为此,人们引入另一种方法:BPE。
BPE 不是按照中文字词为最小单位,而是按照 unicode 编码 作为最小粒度。
对于中文来讲,一个汉字是由 3 个 unicode 编码组成的,
因为平时我们不会拆开来看(毕竟中文汉字是不可拆分的),所以我一开始对这个概念也不太熟悉。
我们来看看 LLaMA 的 tokenizer(BPE)对中文是如何进行 encode 的:
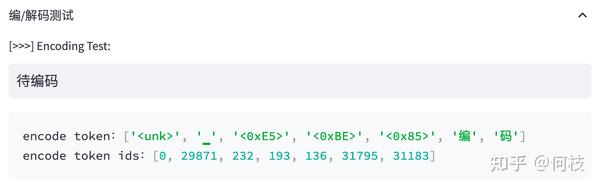
上述图片来自可视化工具 [tokenizer_viewer]。
可以看到,「编码」两个字能够被正常切成 2 个字,
但「待」却被切成了 3 个 token,这里的每个 token 就是 1 个 unicode 编码。
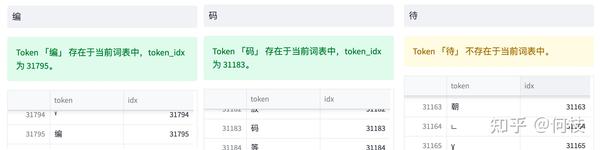
通过 token 查找功能,我们可以发现「编」「码」在词表中,但「待」不在词表中。
但任何 1 个汉字都是可以由 unicode 表示(只是组合顺序不同),因此「待」就被切成了 3 个 token。
BPE 的优势 | 不会出现 OOV 的情况。不管是怎样的汉字,只要可以用 unicode 表示,就都会存在于词表中。 |
BPE 的劣势 | 模型训练起来将会更吃力一些。毕竟像「待」这样的汉字特定 unicode 组合其实是不需要模型学习的,但模型却需要通过学习来知道合法的 unicode 序列。 |
通常在模型训练不够充足的时候,模型会输出一些乱码(不合法的 unicode 序列):
词表扩充
为了降低模型的训练难度,人们通常会考虑在原来的词表上进行「词表扩充」,
也就是将一些常见的汉字 token 手动添加到原来的 tokenizer 中,从而降低模型的训练难度。
我们对比 [Chinese-LLaMA] 和 [LLaMA] 之间的 tokenizer 的区别:
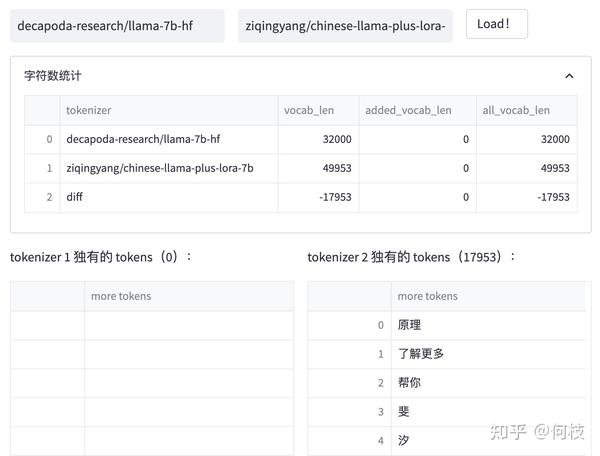
上述图片来自可视化工具 [tokenizer_viewer]。
我们可以发现:Chinese LLaMA 在原始 tokenizer 上新增了17953 个 tokens,且加入 token 的大部分为汉字。
而在 [BELLE] 中也有同样的做法:
在 120w 行中文文本上训练出一个 5w 规模的 token 集合,
并将这部分 token 集合与原来的 LLaMA 词表做合并,
最后再在 3.2B 的中文语料上对这部分新扩展的 token embedding 做二次预训练。

Language Model Pretraining
在扩充完 tokenizer 后,我们就可以开始正式进行模型的预训练步骤了。
Pretraining 的思路很简单,就是输入一堆文本,让模型做 Next token Prediction 的任务,这个很好理解。
我们主要来讨论几种预训练过程中所用到的方法:数据源采样、数据预处理、模型结构。
数据源采样
在 [gpt3] 的训练过程中,存在多个训练数据源,论文中提到:对不同的数据源会选择不同采样比例:
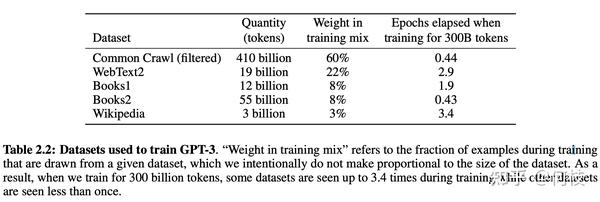
通过「数据源」采样的方式,能够缓解模型在训练的时候受到「数据集规模大小」的影响。
从上图中可以看到,相对较大的数据集(Common Crawl)会使用相对较大的采样比例(60%),
这个比例远远小于该数据集在整体数据集中所占的规模(410 / 499 = 82.1%),
因此,CC 数据集最终实际上只被训练了 0.44(0.6 / 0.82 * (300 / 499))个 epoch。
而对于规模比较小的数据集(Wikipedia),则将多被训练几次(3.4 个 epoch)。
这样一来就能使得模型不会太偏向于规模较大的数据集,从而失去对规模小但作用大的数据集上的学习信息。
数据预处理
数据预处理主要指如何将「文档」进行向量化。
通常来讲,在 Finetune 任务中,我们通常会直接使用 truncation 将超过阈值(2048)的文本给截断,
但在 Pretrain 任务中,这种方式显得有些浪费。
以书籍数据为例,一本书的内容肯定远远多余 2048 个 token,但如果采用头部截断的方式,
则每本书永远只能够学习到开头的 2048 tokens 的内容(连序章都不一定能看完)。
因此,最好的方式是将长文章按照 seq_len(2048)作分割,将切割后的向量喂给模型做训练。
模型结构
为了加快模型的训练速度,通常会在 decoder 模型中加入一些 tricks 来缩短模型训练周期。
目前大部分加速 tricks 都集中在 Attention 计算上(如:MQA[2] 和 Flash Attention[3] [falcon] 等);
此外,为了让模型能够在不同长度的样本上都具备较好的推理能力,
通常也会在 Position Embedding 上进行些处理,选用 ALiBi([Bloom])或 RoPE([GLM-130B])等。
具体内容可以参考下面这篇文章:
数据集清理
中文预训练数据集可以使用 [悟道],数据集分布如下(主要以百科、博客为主):
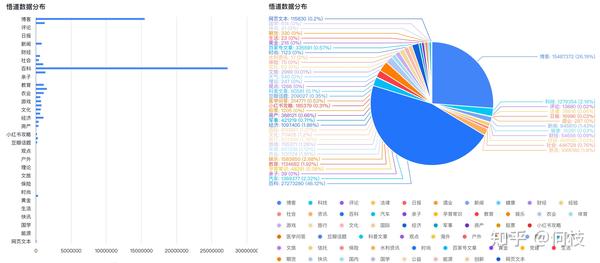
但开源数据集可以用于实验,如果想突破性能,则需要我们自己进行数据集构建。
在 [falcon paper] 中提到,
仅使用「清洗后的互联网数据」就能够让模型比在「精心构建的数据集」上有更好的效果,
一些已有的数据集和它们的处理方法如下:
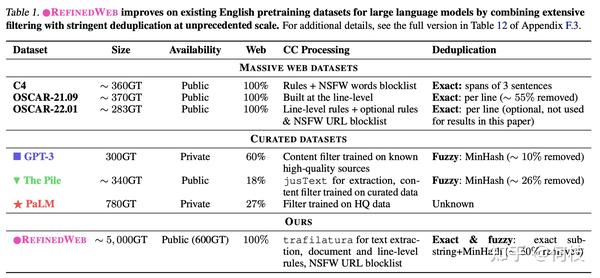
有关 Falcon 更多的细节可以看这里:
模型效果评测
关于 Language Modeling 的量化指标,较为普遍的有 [PPL],[BPC] 等,
可以简单理解为在生成结果和目标文本之间的 Cross Entropy Loss 上做了一些处理。
这种方式可以用来评估模型对「语言模板」的拟合程度,
即给定一段话,预测后面可能出现哪些合法的、通顺的字词。
但仅仅是「生成通顺句子」的能力现在已经很难满足现在人们的需求,
大部分LLM都具备生成流畅和通顺语句能力,很难比较哪个好,哪个更好。
为此,我们需要能够评估另外一个大模型的重要能力 —— 知识蕴含能力。
C-Eval
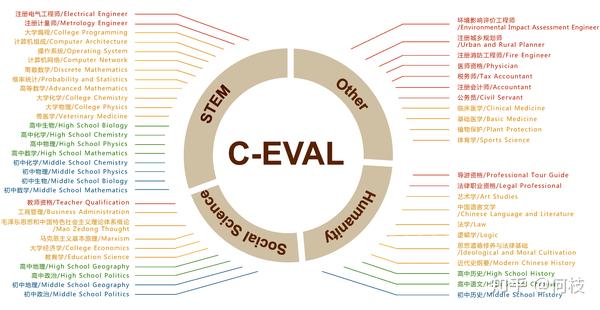
一个很好的中文知识能力测试数据集是 [C-Eval],涵盖1.4w 道选择题,共 52 个学科。
覆盖学科如下:
由于是选择题的形式,我们可以通过将题目写进 prompt 中,
并让模型续写 1 个 token,判断这个续写 token 的答案是不是正确答案即可。
但大部分没有精调过的预训练模型可能无法续写出「A B C D」这样的选项答案,
因此,官方推荐使用 5-shot 的方式来让模型知道如何输出答案:
1 | 以下是中国关于会计考试的单项选择题,请选出其中的正确答案。 |
通过前面的样例后,模型能够知道在「答案:」后面应该输出选项字母。
于是,我们获得模型续写后的第一个 token 的概率分布(logits),
并取出「A B C D」这 4 个字母的概率,通过 softmax 进行归一化:
1 | probs = ( |
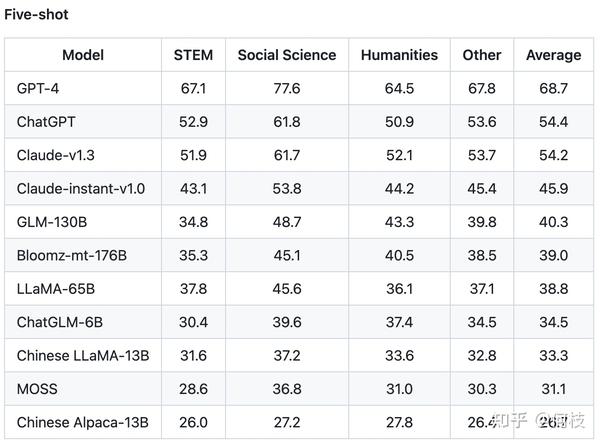
C-Eval 通过这种方式测出了许多模型在中文知识上的效果,
由于是 4 选项问题,所以基线(随机选择)的正确率是 25%。
C-Eval 也再一次证明了 GPT-4 是个多么强大的知识模型:
指令微调阶段Instruction Tuning Stage
在完成第一阶段的预训练后,就可以开始进到指令微调阶段了。
由于预训练任务的本质在于「续写」,而「续写」的方式并一定能够很好的回答用户的问题。
例如:
| 用户问题 | 用户预期回答 | 模型续写结果 |
|---|---|---|
| 《无间道》的主演有哪些? | 刘德华、梁朝伟 | 《无间道》的主演有哪些?不少观众期待看到阵容公告,今天小编… |
因为训练大多来自互联网中的数据,我们无法保证数据中只存在存在规范的「一问一答」格式,
这就会造成预训练模型通常无法直接给出人们想要的答案。
但是,这并不代表预训练模型「无知」,只是需要我们用一些巧妙的「技巧」来引导出答案:
| 用户问题 | 用户预期回答 | 模型续写结果 |
|---|---|---|
| 《无间道》的主演有 | 刘德华、梁朝伟 | 《无间道》的主演有刘德华、梁朝伟和黄秋生,而这部电影也是香港警匪片的代表作之一。 |
不过,这种需要用户精心设计从而去「套」答案的方式,显然没有那么优雅。
既然模型知道这些知识,只是不符合我们人类的对话习惯,那么我们只要再去教会模型「如何对话」就好了。
这就是 Instruction Tuning 要做的事情,即指令对齐。
OpenAI 在 [instruction-following] 中展示了 GPT-3 和经过指令微调前后模型的区别:

Self Instruction
既然我们需要去「教会模型说人话」,
那么我们就需要去精心编写各式各样人们在对话中可能询问的问题,以及问题的答案。
在 [InstructGPT Paper] 中,使用了 1.3w 的数据来对 GPT-3.5 进行监督学习(下图中左 SFT Data):

可以观察到,数据集中人工标注(labeler)占大头,
这还仅仅只是 InstructGPT,和 ChatGPT 远远不是一个量级。
非官方消息:
ChatGPT使用了百万量级的数据进行指令微调。
可见,使用人工标注是一件成本巨大的事情,只是找到人不够,需要找到「专业」且「认知一致」的标注团队。
如果这件事从头开始做自然很难(OpenAI 确实厉害),但今天我们已经有了 ChatGPT 了,
我们让 ChatGPT 来教我们自己的模型不就好了吗?
这就是 Self Instruction 的思路,即通过 ChatGPT 的输入输出来蒸馏自己的模型。
一个非常出名的项目是 [stanford_alpaca]。
如果从 ChatGPT 「套」数据,那么我们至少需要「套」哪些数据。
Instruction Tuning 中的「输入」(问题)和「输出」(答案)是训练模型的关键,
答案很好得到,喂给 ChatGPT 问题根据返回结果就能获得,
但「问题」从哪里获得呢?
(靠人想太累了,屏幕前的你不妨试试,看看短时间内能想出多少有价值的问题)
Alpaca 则是使用「种子指令(seed)」,使得 ChatGPT 既生成「问题」又生成「答案」。
由于 Alpaca 是英文项目,为了便于理解,我们使用相同思路的中文项目 [BELLE] 作为例子。
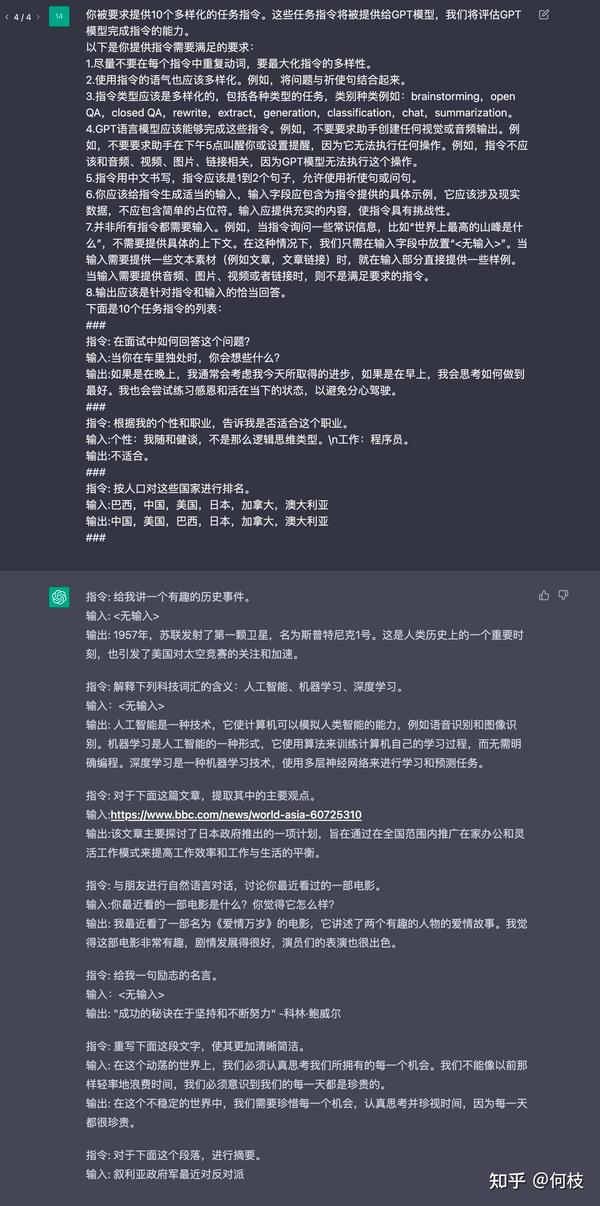
通俗来讲,就是人为的先给一些「训练数据样例」让 ChatGPT 看,
紧接着利用 ChatGPT 的续写功能,让其不断地举一反三出新的训练数据集:
1 | 你被要求提供10个多样化的任务指令。这些任务指令将被提供给GPT模型,我们将评估GPT模型完成指令的能力。 |
如上述例子所示,我们先给出 2 个样例,并让 ChatGPT 进行续写:
关于 BELLE 的更多细节可以参考这篇文章:
开源数据集整理
在这一章中,我们将梳理一些开源的 Instruction Tuning 的数据集,
除了直接拿来用以外,我们期望通过分析这些已有数据集,从而学习如何构建一个指令数据集。
Alpaca
[stanford_alpaca] 采用上述的 Self Instruction 的方式采集了 5200 条指令训练数据集。
数据样例如下:
1 | { |
其中,instruction 代表要求模型做的任务,input 代表用户输入, output 代表喂给模型的 label。
Alpaca 覆盖了多种类型的指令,其数据分布如下:
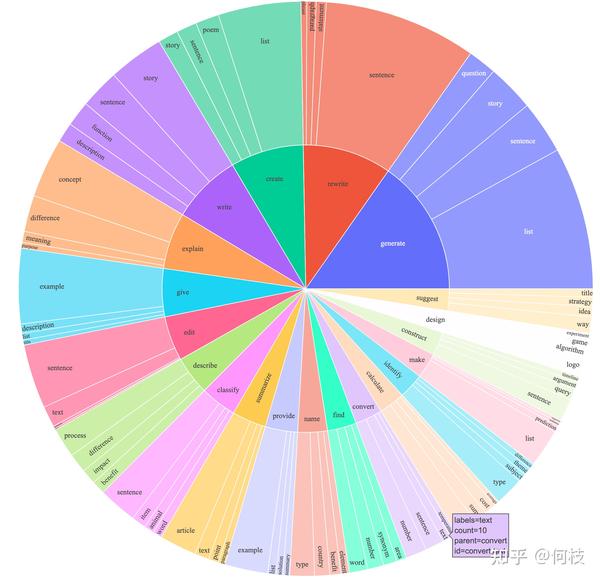
包含写作、描述、分类、摘要等多种类型的任务集合。
BELLE
BELLE 开放了好几种规模的数据集,[100万]、[200万]、[350万] 等。
训练数据集样例如下:
1 | { |
由于数据量很大,我们无法统计出训练数据集中各任务的真实占比,
但从 [1000条评测集] 数据分布可以推测出,训练数据集中同样包含:摘要、问答、分类等任务。
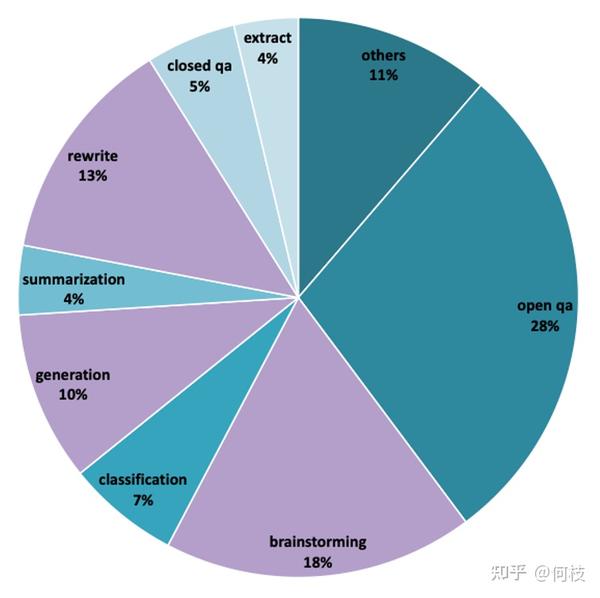
我们按照类别对评测数据进行采样,结果如下:
| 任务名称 | 例子 |
|---|---|
| 文本生成 | 为一种智能手表编写用户手册,包括详细的使用说明和操作步骤。 |
| 头脑风暴 | 针对给定的主题,进行头脑风暴并记录所有想法。 |
如何提高公司的销售额? |
| 开放域问答 | 用一两句话描述著名的尼罗河是如何形成的。 |
| 封闭域问答 | 从以下选项中选择正确的词汇填空以完整下面的句子。 他喜欢去_______看电影。A) 邮局 B)超市 C)电影院 D)音乐会 |
| 分类 | 请将以下这篇文章分类为新闻报道、科学文章或社论。
据媒体新闻援引美国福克斯新闻网报道,美国伯克希尔哈撒韦公司首席执行官、著名投资人巴菲特近日就美国银行业危机与总统拜登的团队进行对话。 |
| 抽取 | 基于以下表格,请问张三的考勤情况
员工姓名,日期,上班时间,下班时间,是否迟到,是否早退,是否请假
张三,1月1日,8:30,17:30,否,否,否
李四,1月1日,9:00,18:00,是,否,否
王五,1月1日,8:00,16:30,否,是,否
赵六,1月1日,8:30,17:00,否,否,是
张三,1月2日,8:00,17:00,否,否,否
李四,1月2日,8:30,17:30,否,否,否
王五,1月2日,9:00,18:00,是,否,否
赵六,1月2日,8:30,17:00,否,否,是 |
| 重写 | 根据提供的文本重写其中的一段,使之更加简明扼要,同时不丢失原文本的主要信息。
纽约市,简称“纽约”,通常被称为“大苹果”,是美国最大的城市,也是全世界最大的城市之一。位于美国东海岸,东北部边界是大西洋,在新泽西州的东南部。 |
| 摘要 | 基于下面的这个故事,总结其中最重要的三个事件。
小明是一个好学生,每天早上都要起得很早去上学。有一天,他迟到了,因为他的家里来了一个客人。晚上,他参加了一次班级会议,会议主题是如何提高学习效率。回到家后,他又花了一些时间复习功课。 |
| Code & Math | 按照以下要求,写一个SQL查询语句:从表中查找所有性别为女性的学生的姓名和学号。
SELECT name, id FROM students WHERE gender = ‘女性’ |
Vicuna
BAIZE
模型的评测方法
比起预训练(Pretrain)环节里相对明确的评价指标(如PPL、NLL等),
Instruction 环节中的评价指标比较令人头疼。
鉴于语言生成模型的发展速度,BLEU 和 ROUGH 这样的指标已经不再客观。
一种比较流行的方式是像 [FastChat] 中一样,利用 GPT-4 为模型的生成结果打分,
我们也尝试使用同样的 prompt 对 3 种开源模型:OpenLlama、ChatGLM、BELLE 进行测试。
注意:下面的测试结果仅源自我们自己的实验,不具备任何权威性。
对于每一个问题,我们先获得 ChatGPT 的回复,以及另外 3 种模型的回复,
接着我们将 「ChatGPT 答案 - 候选模型答案」这样的 pair 喂给 GPT-4 打分(满分为 10 分)。
得到的结果如下:
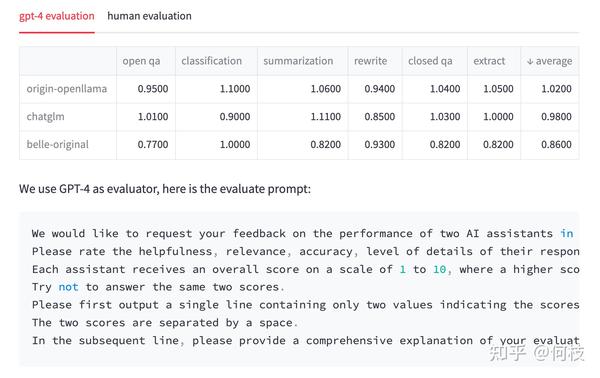
我们对每个任务单独进行了统计,并在最后一列求得平均值。
GPT-4 会对每一条测试样本的 2 个答案分别进行打分,并给出打分理由:
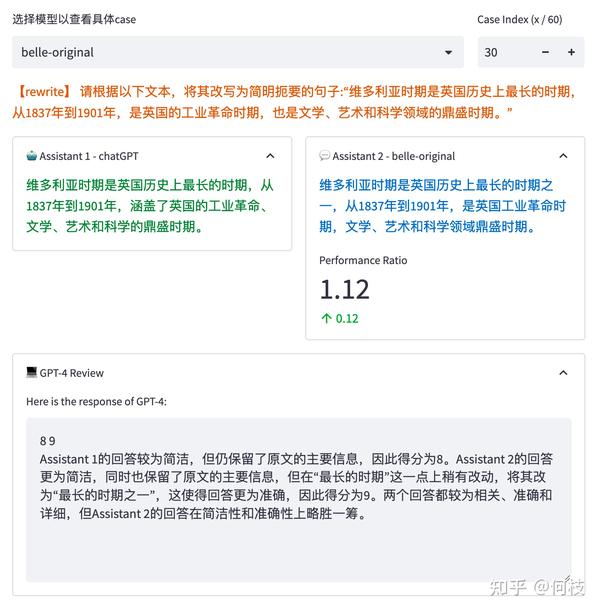
但是,我们发现,GPT-4 打出的分数和给出理由并不一定正确。
如上图所示,GPT-4 为右边模型的答案打出了更高的分数,给出的理由是:
将「最长时期」改为了「最长时期之一」会更准确。
但事实上,Instruction 中明确设定就是「最长时期」,
这种「给高分」的理由其实是不正确的。
此外,我们还发现,仅仅调换句子顺序也会对最后打分结果产生影响,
针对这个问题,我们考虑「调换句子顺序并求和平均」来缓解。
但不管怎么样,GPT-4 给出的分数或许并没有我们想象中的那么靠谱,
为此,我们通过人工的 Review 的方式对每个答案进行了一次回扫,得到的结果和标准如下:
再次重申:我们只是期望指出
GPT-4打分可能会和实际产生偏差的问题,这里排名不具备任何权威性。
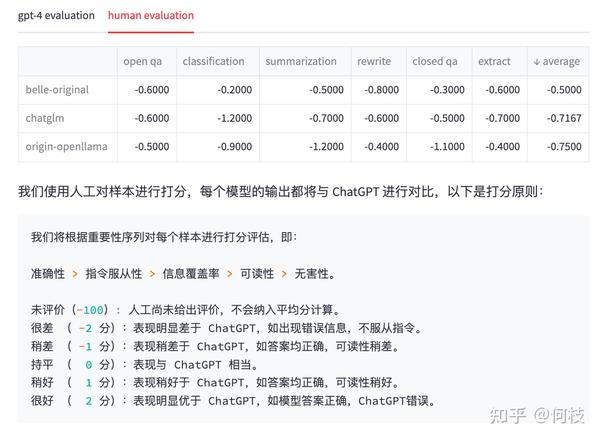
我们可以看到,
在 GPT-4 打分的结果中,已经有模型的效果甚至超过了 ChatGPT(分数为 1.02),
但再经过人工 Review 后,ChatGPT 的答案是我们认为更合理一些的。
当然,最近陆陆续续的推出了许多新的评测方法,如:[PandaLM],
以及许多比较有影响力的评测集,如:[C-Eval]、[open_llm_leaderboard] 等,
我们或许会在后续的整理中更新。
专有名词解释
soft fine tuning
Soft Fine-Tuning for Cross-Domain Transfer Learning(软精调用于跨领域迁移学习)是一种用于解决跨领域迁移学习问题的方法。
该方法旨在通过在源领域和目标领域之间进行知识传递,从而提高目标领域的性能。Soft Fine-Tuning方法的核心思想是将源领域和目标领域的数据进行对齐,然后使用源领域的知识来指导目标领域的学习过程。
具体而言,该方法使用一个共享的特征提取器来提取源领域和目标领域的特征表示。
然后,通过最小化源领域和目标领域之间的特征分布差异来对特征进行对齐。最后,使用源领域的标签信息来辅助目标领域的学习过程,以提高目标领域的性能。
- 论文:
Soft Fine-Tuning for Cross-Domain Transfer Learning GitHub代码实现:- 链接:待定
MQA
总 结:MQA是指多头自注意力(Multi-Head Self-Attention)机制,是一种在自注意力机制中引入多个头部的方法。背 景:自注意力机制是一种在序列中计算每个位置与其他位置的关联性的方法,通过计算每个位置与其他位置的相似度得到一个权重向量,用于加权求和得到每个位置的表示。主要贡献:MQA则是在计算相似度时引入了多个头部,每个头部计算一种不同的相似度。目 的:
1、通过引入多个头部,可以捕捉到不同的关系和语义信息,提高模型的表达能力。
2、提高模型在处理序列数据时的性能。
Flash Attention
总 结:Flash Attention是一种注意力机制,通过引入全局上下文信息,能够更全面地捕捉序列数据中的依赖关系,用于提高神经网络在处理序列数据时的性能。
背 景:在序列数据中,每个元素都与其周围的元素相关联,而传统的注意力机制通常只考虑了元素之间的局部关系。主要贡献:通过引入全局上下文信息,能够更全面地捕捉序列数据中的依赖关系。具体做法:
1、通过将序列数据分为多个子序列,每个子序列都包含了原始序列数据的一部分。
2、然后,每个子序列都会与其他子序列进行交互,以获取全局上下文信息。这种交互可以通过不同的方式实现,例如计算子序列之间的相似度得分,然后根据得分来决定信息的传递程度。目 的:1、捕捉序列数据中的依赖关系 2、提高神经网络在处理序列数据时的性能论 文: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness论文总结:
这段内容讨论了Transformer模型在处理长序列时的速度和内存消耗问题。由于自注意力机制的时间和内存复杂度与序列长度的平方成正比,因此Transformer在长序列上运行得比较慢且消耗大量内存。近似注意力方法试图通过在模型质量和计算复杂度之间进行权衡来解决这个问题,但通常不能实现显著的速度提升。作者认为一个缺失的原则是使注意力算法能够考虑输入输出(I/O)操作,即在不同层级的GPU内存之间进行读写操作。作者提出了一种名为FlashAttention的I/O感知精确注意力算法,使用分块技术来减少GPU高带宽内存(HBM)和GPU片上静态随机存储器(SRAM)之间的内存读写次数。作者分析了FlashAttention的I/O复杂度,表明它需要比标准注意力更少的HBM访问次数,并且对于一定大小的SRAM是最优的。作者还将FlashAttention扩展到了块稀疏注意力,得到了一种比任何现有的近似注意力算法更快的近似注意力算法。FlashAttention在训练Transformer模型方面表现比现有基准更快:相较于MLPerf 1.1训练速度记录,BERT-large (seq. length 512)的端到端墙时钟速度提升了15%,GPT-2 (seq. length 1K)的速度提升了3倍,长距离竞技场 (seq. length 1K-4K)的速度提升了2.4倍。FlashAttention和块稀疏FlashAttention使得Transformer模型可以处理更长的上下文,从而得到更高质量的模型(GPT-2 perplexity提高了0.7,长文档分类达到了6.4个点的提升),并且实现了全新的能力:在Path-X挑战赛上,它是首个在序列长度为16K时达到超过随机猜测准确率的Transformer模型(61.4%准确率),在Path-256挑战赛上,则是序列长度为64K时获得超过随机猜测准确率的首个Transformer模型(63.1%准确率)。
ALiBi的position embedding
ALiBi是阿里巴巴开发的一个自然语言处理模型,它在Transformer模型中使用了position embedding来编码输入序列中每个单词的位置信息。
在Transformer模型中,输入序列的每个单词都会经过一个embedding层进行编码,将其转换为一个固定维度的向量表示。然而,由于Transformer模型是基于注意力机制的,它并没有对输入序列的顺序进行建模。为了引入位置信息,Transformer模型引入了position embedding。
position embedding是一个与输入序列的位置相关的向量。它的维度与单词的embedding维度相同,但是每个位置上的值是不同的。通过将position embedding与单词的embedding相加,可以将位置信息融入到输入向量中。
具体来说,position embedding是通过一个特殊的矩阵进行计算得到的。这个矩阵的维度是(positions, embedding_dim),其中positions表示输入序列的最大长度,embedding_dim表示单词embedding的维度。矩阵中的每一行对应一个位置,每一列对应embedding向量的一个维度。通过查表的方式,可以获取到输入序列中每个单词的位置编码。
在ALiBi中,position embedding会与单词的embedding相加,然后作为输入传递给Transformer模型。这样,Transformer模型就能够同时考虑到单词的语义信息和位置信息,从而更好地理解输入序列。