004 大模型微调总结-知乎-绝密伏击
转载
本文转载于:@知乎-绝密伏击
总结
| 年份 | inc | method | 创新之处 | 参数 | 哪一层 | 位置 | 初始化方式 | 前辈 | 论文 |
|---|---|---|---|---|---|---|---|---|---|
| 2019 | 谷歌 | Adapter Tuning |
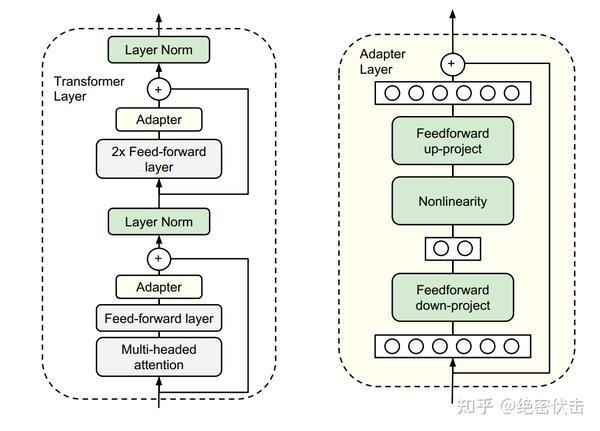
1、设计Adapter结构(即MLP),嵌入 Transformer 的结构2、Adapter 结构: - down-project层:将高维度特征映射到低维特征。 - 非线性层 ReLU:对低维特征进行处理,以更好地表达特征信息。- up-project结构:将低维特征映射回原来的高维特征。 - skip-connection结构:确保即使在最差的情况下,模型仍能正确处理输入特征,类似于残差结构。 |
+3.6% | Transformer ffn和layerNorm之间 |
《Parameter-Efficient Transfer Learning for NLP》 | |||
| 年份 | inc | method | 创新之处 | 参数 | 哪一层 | 位置 | 初始化方式 | 前辈 | 论文 |
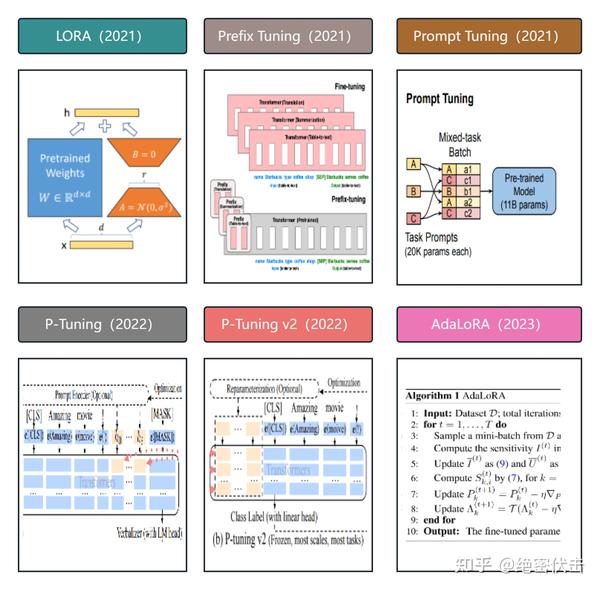
| 2021 | 斯坦福 | Prefix Tuning |
1、在每个Attention 层 输入token 之前构造一段任务相关的 virtual tokens 作为 Prefix2、固定预训练参数,训练只更新 Prefix 部分的参数。该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而 Prefix 则是可以学习的“隐式”的提示。3、防止直接更新 Prefix 的参数导致训练不稳定的情况,在 Prefix 层前面加了 MLP 结构(相当于将 Prefix 分解为更小维度的 Input与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。 |
+0.1% | Attention head |
输入token 之前 |
MLP |
《Prefix-Tuning: Optimizing Continuous Prompts for Generation》 | |
| 年份 | inc | method | 创新之处 | 参数 | 哪一层 | 位置 | 初始化方式 | 前辈 | 论文 |
| 2021 | 谷歌 | Prompt Tuning |
1、Prefix Tuning 的简化版本,只在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题2、固定预训练参数,为每一个任务额外添加一个或多个 embedding,之后拼接 query 正常输入 LLM,并只训练这些 embedding。 |
未知 | 输入层 | 输入token 之前 |
无 | Prefix Tuning |
《The Power of Scale for Parameter-Efficient Prompt Tuning》 |
| 年份 | inc | method | 创新之处 | 参数 | 哪一层 | 位置 | 初始化方式 | 前辈 | 论文 |
| 2022 | 清华 | P-Tuning |
1、背景:大模型的显式Prompt构造方式严重影响下游任务的效果2、将 Prompt 转换为可以学习的 Embedding 层3、提出用 MLP + BiLSTM 的方式来对 prompt embedding 进行一层处理4、固定预训练参数,利用 MLP+LSTM 对 Prompt 进行编码,编码之后与其他向量进行拼接之后正常输入 LLM。训练之后只保留 Prompt 编码之后的向量,不保留编码器。5、输入的时候加入 Embedding,Embedding位置则不固定 |
0.0586% | 输入层 | 不固定 | MLP + BiLSTM |
显式Prompt |
《GPT Understands, Too》 |
| 年份 | inc | method | 创新之处 | 参数 | 哪一层 | 位置 | 初始化方式 | 前辈 | 论文 |
| 2022 | 清华 | P-Tuning v2 |
1、背景:Prompt Tuning、P-Tuning在小参数量模型(<10B)上表现差,在sequence tagging任务上表现都很差 2、目标:让 Prompt Tuning 能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到敌Fine-tuning 的结果3、在多层加入了 Prompts tokens 作为输入,加深参数数量和深度 |
13.26% | 每一层 | 输入token 之前 |
未知 | Prompt Tuning、P-Tuning |
《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》 |
| 年份 | inc | method | 创新之处 | 参数 | 哪一层 | 位置 | 初始化方式 | 前辈 | 论文 |
| 2021 | 微软 | LoRA |
在大型语言模型上对指定参数增加额外的低秩矩阵,并在模型训练过程中,仅训练而外增加的参数 |
0.0586% | attn key/val |
《LoRA: Low-Rank Adaptation of Large Language Models》 | |||
| 年份 | inc | method | 创新之处 | 参数 | 哪一层 | 位置 | 初始化方式 | 前辈 | 论文 |
| 2023 | 微软 | AdaLORA |
1、背 景:预训练语言模型中的权重参数对下游任务的贡献是不同的,需要更加智能分配参数预算,以在微调过程中更高效地更新贡献较大的参数。2、主要贡献:使用 奇异值分解将权重矩阵分解为增量矩阵,并根据重要性度量动态调整增量矩阵中奇异值的大小。 |
未知 | LoRA |
《adaptive budget allocation for parameterefficient fine-tuning》 |
引言
最近,深度学习的研究中出现了许多大型预训练模型,例如 GPT-3、ChatGPT、GPT4、ChatGLM-130B 等,这些模型可以在多种自然语言处理任务中取得优异的性能表现。而其中,ChatGPT 模型因为在对话生成方面的表现而备受瞩目,成为了自然语言处理领域的热门研究方向。
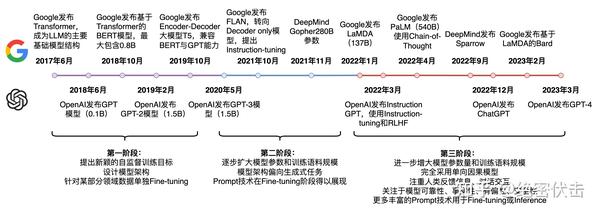
然而,这些大型预训练模型的训练成本非常高昂,需要庞大的计算资源和大量的数据,一般人难以承受。这也导致了一些研究人员难以重复和验证先前的研究成果。为了解决这个问题,研究人员开始研究 Parameter-Efficient Fine-Tuning (PEFT) 技术。PEFT 技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。因此,PEFT 技术可以在提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究中来。
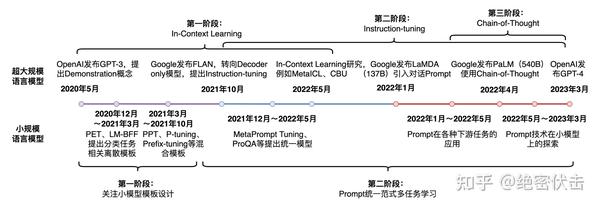
在上一篇文章中,介绍了 PEFT 技术中的常用方法 LORA,使得百亿(10B)参数的大模型可以在单卡上训练(显存大小>=40G)。
今天介绍下另外几种常用的方法,包括 Adapter Tuning、Prompt Tuning、Prefix Tuning、P-Tuning、P-Tuning v2 和 AdaLORA。
Adapter Tuning
2019年谷歌的研究人员首次在论文《Parameter-Efficient Transfer Learning for NLP》提出针对 BERT 的 PEFT微调方式,拉开了 PEFT 研究的序幕。他们指出,在面对特定的下游任务时,如果进行 Full-Fintuning(即预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
于是他们设计了如下图所示的 Adapter 结构,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将Adapter设计为这样的结构:
- 首先是一个
down-project层将高维度特征映射到低维特征 - 然后过一个非线形层之后,再用一个
up-project结构将低维特征映射回原来的高维特征 - 同时也设计了
skip-connection结构,确保了在最差的情况下能够退化为identity(类似残差结构)。
从实验结果来看,该方法能够在只额外对增加的 3.6% 参数规模(相比原来预训练模型的参数量)的情况下取得和Full-Finetuning 接近的效果(GLUE指标在0.4%以内)。
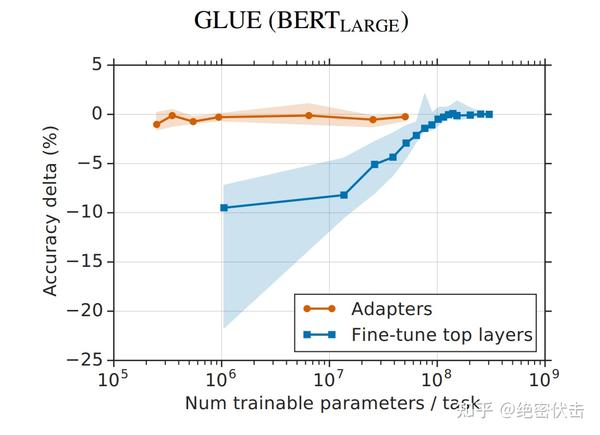
Prefix Tuning
2021年斯坦福的研究人员在论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》中提出了 Prefix Tuning 方法。与Full-Finetuning 更新所有参数的方式不同,该方法是在 输入token 之前构造一段任务相关的 virtual tokens 作为 Prefix ,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而 Prefix 则是可以学习的“隐式”的提示。
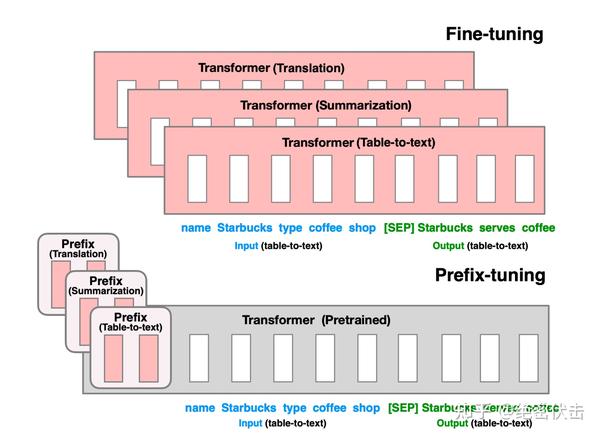
同时,为了防止直接更新 Prefix 的参数导致训练不稳定的情况,他们在 Prefix 层前面加了 MLP 结构(相当于将 Prefix 分解为更小维度的 Input与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。
1 | embedding = torch.nn.Embedding(num_virtual_tokens, token_dim) |
Prompt Tuning
Prompt Tuning 是2021年谷歌在论文《The Power of Scale for Parameter-Efficient Prompt Tuning》中提出的微调方法。
该方法可以看作是 Prefix Tuning 的简化版本,只在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题,主要在 T5 预训练模型上做实验。似乎只要预训练模型足够强大,其他的一切都不是问题。作者也做实验说明随着预训练模型参数量的增加,Prompt Tuning的方法会逼近 Fine-tune 的结果。
固定预训练参数,为每一个任务额外添加一个或多个embedding,之后拼接 query 正常输入 LLM,并只训练这些 embedding。左图为单任务全参数微调,右图为 Prompt Tuning。
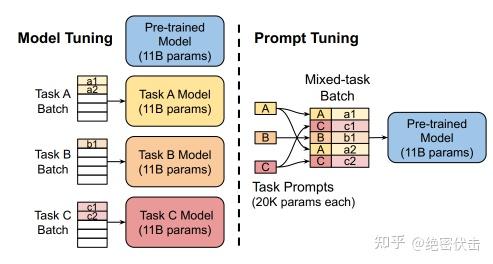
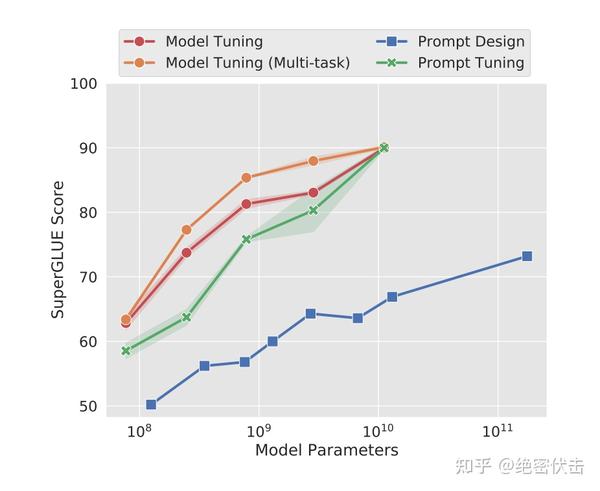
作者做了一系列对比实验,都在说明:随着预训练模型参数的增加,一切的问题都不是问题,最简单的设置也能达到极好的效果。
Prompt长度影响:模型参数达到一定量级时,Prompt长度为1也能达到不错的效果,Prompt长度为20就能达到极好效果。Prompt初始化方式影响:Random Uniform方式明显弱于其他两种,但是当模型参数达到一定量级,这种差异也不复存在。- 预训练的方式:
LM Adaptation的方式效果好,但是当模型达到一定规模,差异又几乎没有了。 - 微调步数影响:模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,
zero shot也能取得不错效果。 - 当参数达到100亿规模与全参数微调方式效果无异。
1 | from PEFT import PromptTuningConfig, get_PEFT_model |
P-Tuning v1
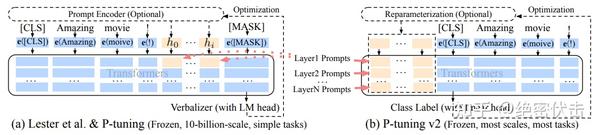
P-Tuning 方法的提出主要是为了解决这样一个问题:大模型的 Prompt 构造方式严重影响下游任务的效果。

P-Tuning 提出将 Prompt 转换为可以学习的 Embedding 层,只是考虑到直接对 Embedding 参数进行优化会存在这样两个挑战:
Discretenes: 对输入正常语料的Embedding层已经经过预训练,而如果直接对输入的prompt embedding进行随机初始化训练,容易陷入局部最优。Association:没法捕捉到prompt embedding之间的相关关系。
作者在这里提出用 MLP + BiLSTM 的方式来对 prompt embedding 进行一层处理:
P-Tuning 依然是固定 LLM 参数,利用MLP+LSTM 对 Prompt 进行编码,编码之后与其他向量进行拼接之后正常输入 LLM。注意,训练之后只保留 Prompt 编码之后的向量即可,无需保留编码器。
1 | self.lstm_head = torch.nn.LSTM( |
与Prefix-Tuning的区别
P-Tuning 和 Prefix Tuning 差不多同时提出,做法其实也有一些相似之处,主要区别在:
Prefix Tuning是将额外的embedding加在开头,看起来更像是模仿Instruction指令;而P-Tuning的位置则不固定。Prefix Tuning通过在每个Attention层都加入Prefix Embedding来增加额外的参数,通过MLP来初始化;而P-Tuning只是在输入的时候加入Embedding,并通过LSTM+MLP来初始化。
P-Tuning v2
P-Tuning 的问题是在小参数量模型上表现差(如上图所示)。
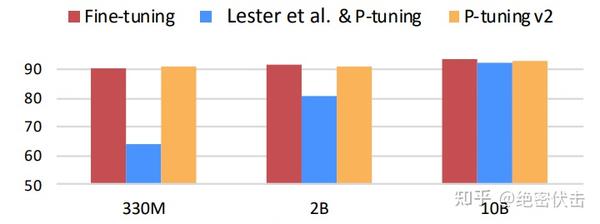
于是就有了v2版本:《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》。
从标题就可以看出,P-Tuning v2 的目标就是要让 Prompt Tuning 能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning 的结果。
那也就是说当前 Prompt Tuning 方法在这两个方面都存在局限性。
- 不同模型规模:
Prompt Tuning和P-Tuning这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning 类似的效果,而参数规模较小时效果则很差。 - 不同任务类型:
Prompt Tuning和P-Tuning这两种方法在sequence tagging任务上表现都很差。
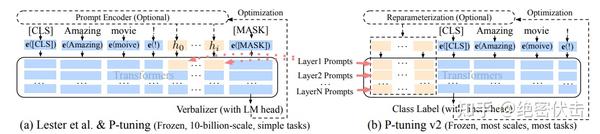
主要结构
相比 Prompt Tuning 和 P-Tuning 的方法, P-Tuning v2 方法在多层加入了 Prompts tokens 作为输入,带来两个方面的好处:
- 带来更多可学习的参数(从
P-Tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够parameter-efficient。 - 加入到更深层结构中的
Prompt能给模型预测带来更直接的影响。
v1 到 v2 的可视化:蓝色部分为参数冻结,橙色部分为可训练部分。
几个关键设计因素
- Reparameterization:
Prefix Tuning和P-Tuning中都有MLP来构造可训练的 embedding。本文发现在自然语言理解领域,面对不同的任务以及不同的数据集,这种方法可能带来完全相反的结论。 - Prompt Length: 不同的任务对应的最合适的 Prompt Length 不一样,比如简单分类任务下 length=20 最好,而复杂的任务需要更长的 Prompt Length。
- Multi-task Learning 多任务对于
P-Tuning v2是可选的,但可以利用它提供更好的初始化来进一步提高性能。 - Classification Head 使用 LM head 来预测动词是
Prompt Tuning的核心,但我们发现在完整的数据设置中没有必要这样做,并且这样做与序列标记不兼容。P-Tuningv2</code> 采用和BERT一样的方式,在第一个token处应用随机初始化的分类头。
实验结果
- 不同预训练模型大小下的表现,在小模型下取得与
Full-Finetuning相近的结果,并远远优于P-Tuning。 - 不同任务下的
P-Tuning v2效果都很好,而P-Tuning和Prompt Learning效果不好;同时,采用多任务学习的方式能在多数任务上取得最好的结果。
AdaLORA
背 景: 预训练语言模型中的权重参数对下游任务的贡献是不同的,需要更加智能地分配参数预算,以在微调过程中更高效地更新贡献较大的参数。主要贡献: 提出了一种通过奇异值分解将权重矩阵分解为增量矩阵,并根据重要性度量动态调整增量矩阵中奇异值的大小的方法,以提高模型性能和参数效率。具体做法: 使用奇异值分解将权重矩阵分解为增量矩阵,并根据重要性度量动态调整增量矩阵中奇异值的大小。通过这种方式,只更新对模型性能贡献较大或必要的参数。目 的: 提高预训练语言模型在微调过程中的参数效率,使其能更高效地更新对模型性能贡献较大的参数,从而提升模型性能。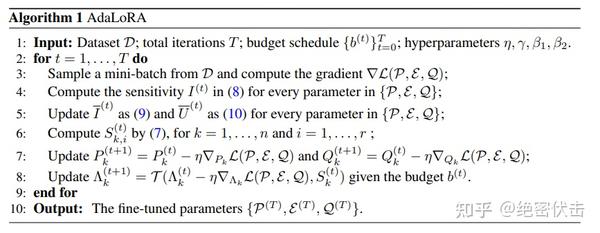
Towards a Unified View of PETL
这篇 ICLR2022 的文章研究了典型的 PEFT 方法,试图将 PEFT 统一到一个框架下,找出它们起作用的具体原因,并进行改进。主要研究了三个问题:
- 典型的
PEFT方法有什么联系? - 典型的
PEFT方法中是哪些关键模块在起作用? - 能否对这些关键模块进行排列组合,找出更有用的
PEFT方法?
通用形式
通过对 Prefix Tuning 的推导,得出了和 Adapter Tuning 以及 LORA 形式一致的形式。
通过对Prefix Tuning的推导,得出了和Adapter Tuning以及LORA形式一致的形式。
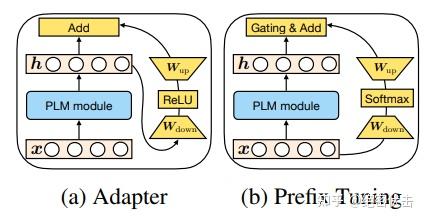
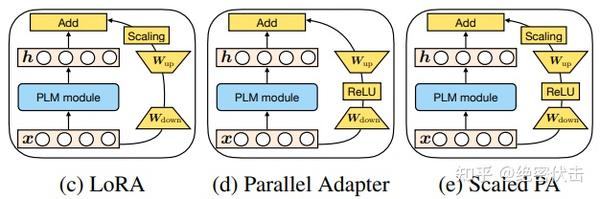
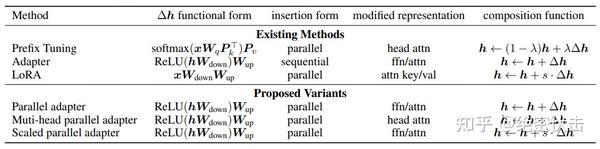
包括这几大要素:
的形式 - 嵌入
Transformer结构的方式(分为Parrell和Sequential两种。 Parallel指的是在输入层嵌入,这样与原有结构可以并行计算Sequential指的是在输出层嵌入,相当于增加了网路的深度,与原有结构存在依赖关系)- 修改表示层(主要指对
attention层的修改还是对ffn层的修改) - 组合方式。怎么与原有的参数组合,包括简单相加(
Adapter)、门控式(Prefix Tuning)、缩放式(LORA)三种)
根据这个统一的框架,还另外设计了三种变体 Parallel Adapter、Multi-head Parallel Adapter、Scaled Parallel Adapter。
参考
- Ladder Side-Tuning:预训练模型的“过墙梯”
- INTRINSIC DIMENSIONALITY EXPLAINS THE EFFECTIVENESS OF LANGUAGE MODEL FINE-TUNING
- Prompt-Tuning——深度解读一种新的微调范式
- P-Tuning:自动构建模版,释放语言模型潜能
- P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- https://aclanthology.org/2022.acl-short.8.pdf
- https://arxiv.org/pdf/2110.07602.pdf
- https://www.yuque.com/meta95/hmc3l4/ozgy13dx4akv7v17?singleDoc#
- 无数据不智能:大模型训练之微调篇
- https://arxiv.org/pdf/2303.10512.pdf
- GitHub - huggingface/PEFT: PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.
- https://arxiv.org/pdf/2110.04366.pdf